两个文件,一个是用户的数据,一个是交易的数据。
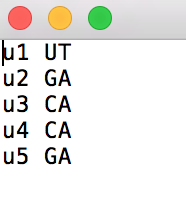
用户:
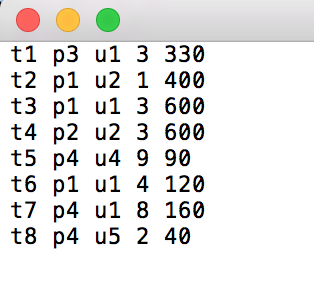
交易:
流程如下:
分为以下几个步骤: (1)分别读取user文件和transform文件,并转为两个RDD.
* (2)对上面两个RDD执行maptopair操作。生成userpairRdd和transformpairRdd
* (3)对transformpairRdd和userpairRdd执行union操作,就是把上面的数据放在一起,生成allRdd
* (4)然后把allRdd用groupBykey分组,把同一个UserID的数据都放在一起。生成groupRdd。
* (5)对grouprdd处理,生成productLoctionRdd:(p1,UT),(p2,UT)这种productlistRdd。
* (6)productlistRdd这里面有数据重复,需要去重。
代码结构:
![]()
代码:
package com.test.book;import java.util.ArrayList;import java.util.HashSet;import java.util.Iterator;import java.util.List;import java.util.Set;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaPairRDD;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.api.java.function.Function;import org.apache.spark.api.java.function.PairFlatMapFunction;import org.apache.spark.api.java.function.PairFunction;import scala.Tuple2;public class LeftJoinCmain { /* * 分为以下几个步骤: (1)分别读取user文件和transform文件,并转为RDD. * (2)对上面两个RDD执行maptopair操作。生成userpairRdd和transformpairRdd * (3)对transformpairRdd和userpairRdd执行union操作,就是把上面的数据放在一起,生成allRdd * (4)然后把allRdd用groupBykey分组,把同一个UserID的数据都放在一起。生成groupRdd。 * (5)对grouprdd处理,生成productLoctionRdd:(p1,UT),(p2,UT)这种productlistRdd。 * (6)productlistRdd这里面有数据重复,需要去重。 * */ public static void main(String[] args) { SparkConf conf = new SparkConf().setAppName("LeftJoinCmain").setMaster("local"); JavaSparkContext sc = new JavaSparkContext(conf); // 导入user的数据 JavaRDD user = sc.textFile("/Users/mac/Desktop/user.txt"); // 导入transform的数据 JavaRDD transform = sc.textFile("/Users/mac/Desktop/transactions.txt"); // 生成一个JavaPairRDD,KEY是uerID,Value是Tuple的形式,("L",地址) JavaPairRDD > userpairRdd = user .mapToPair(new PairFunction >() { /** * */ private static final long serialVersionUID = 1L; @Override public Tuple2 > call(String line) throws Exception { String[] args = line.split(" "); return new Tuple2 >(args[0], new Tuple2 ("L", args[1])); } }); // 生成一个transform, JavaPairRDD > transformpairRdd = transform .mapToPair(new PairFunction >() { /** * */ private static final long serialVersionUID = 1L; @Override public Tuple2 > call(String line) throws Exception { String[] args = line.split(" "); return new Tuple2 >(args[2], new Tuple2 ("P", args[1])); } }); /** * allRdd的格式是: { (userID,Tuple("L","UT")), (userID,Tuple("P","p3")) . . . } */ JavaPairRDD > allRdd = userpairRdd.union(transformpairRdd); /** * 这一步就是把同一个uerID的数据放在一起,结果是: (userID1,List[(Tuple2("L","UT"),//一个用户地址信息 * Tuple2("P","p1"),//其他的都是商品信息 Tuple2("P","p2") ] ) */ JavaPairRDD >> groupRdd = allRdd.groupByKey(); /** * 这一步就是从groupRdd中去掉userID,生成productLoctionRdd:(p1,UT),(p2,UT)这种。 * */ JavaPairRDD productlistRdd = groupRdd.flatMapToPair( new PairFlatMapFunction >>, String, String>() { @Override public Iterable > call(Tuple2 >> t) throws Exception { String location = "UNKNOWN"; Iterable > pairs = t._2; List products = new ArrayList (); for (Tuple2 pair : pairs) { if (pair._1.equals("L")) location = pair._2; if (pair._1.equals("P")) { products.add(pair._2); } } List > kvList = new ArrayList >(); for (String product : products) { kvList.add(new Tuple2 (product, location)); } return kvList; } }); // 把一个商品的所有地址都查出来 JavaPairRDD > productbylocation = productlistRdd.groupByKey(); List >> debug3 = productbylocation.collect(); for (Tuple2 > value : debug3) { Iterator iterator = value._2.iterator(); while (iterator.hasNext()) { System.out.println(value._1 + ":" + iterator.next()); } } /** * 上述代码经过调试, 结果如下: p2:GA p4:GA p4:UT p4:CA p1:UT p1:UT p1:GA p3:UT * * * 发现有相同的商品和地址。我们需要把这个重复的结果去除。 */ // 处理如下:我们用mapvalues()函数 JavaPairRDD , Integer>> productByuniqueLocation = productbylocation .mapValues(new Function , Tuple2 , Integer>>() { @Override public Tuple2 , Integer> call(Iterable v1) throws Exception { Set uniquelocations = new HashSet (); Iterator iterator = v1.iterator(); while (iterator.hasNext()) { String value = iterator.next(); uniquelocations.add(value); } // 返回一个商品的所有地址,以及地址的个数。 return new Tuple2 , Integer>(uniquelocations, uniquelocations.size()); } }); List , Integer>>> finalresult = productByuniqueLocation.collect(); for (Tuple2 , Integer>> vTuple2 : finalresult) { String aa=vTuple2._1; Iterator iterator=vTuple2._2._1.iterator(); while(iterator.hasNext()) { System.out.println("商品的名字:"+aa+"所有的地址"+iterator.next()); } } }}
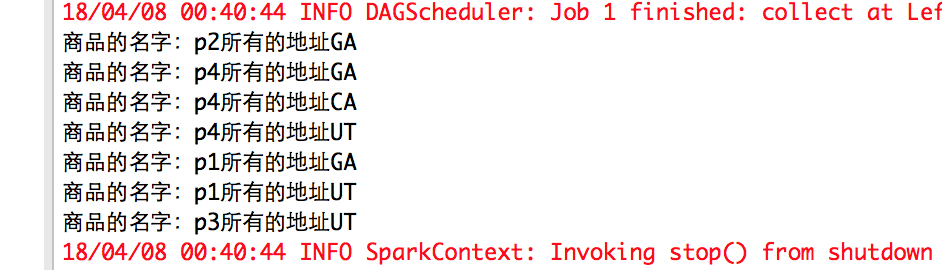
运行结果:

去重后的结果: